
新鲜 / 健康 / 便利 / 快速 / 放心

1995年,Srinivas和Deb提出了非支配排序遗传算法(Non-dominated?Sorting Genetic Algorithms,NSGA)。这是一种基于Pareto最优概念的遗传算法。
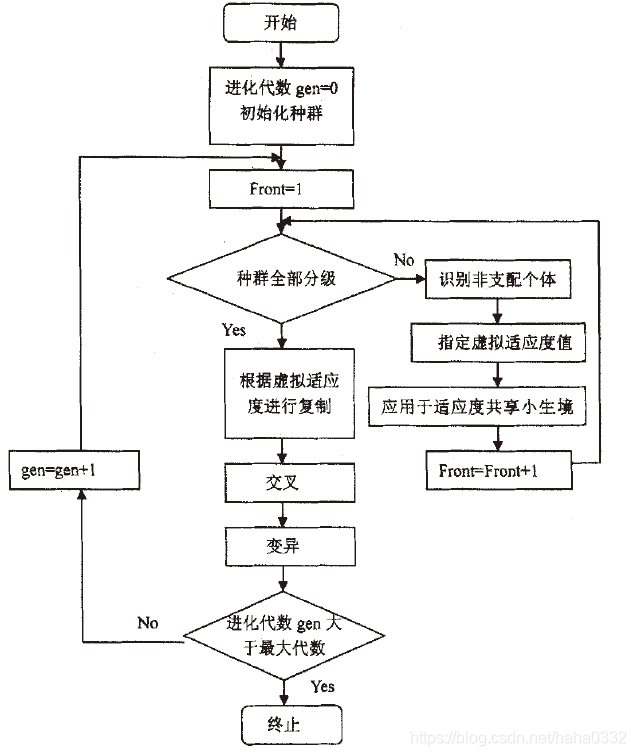
NSGA与简单的遗传算法的主要区别在于:该算法在选择算子执行之前根据个体之间的支配关系进行了分层。其选择算子、交叉算子和变异算子与简单遗传算法没有区别。
在选择操作执行之前,种群根据个体之间的支配与非支配关系进行排序:
首先,找出该种群中的所有非支配个体,并赋予他们一个共享的虚拟适应度值。得到第一个非支配最优层;
然后,忽略这组己分层的个体,对种群中的其它个体继续按照支配与非支配关系进行分层,并赋予它们一个新的虚拟适应度值,该值要小于上一层的值,对剩下的个体继续上述操作,直到种群中的所有个体都被分层。
算法根据适应度共享对虚拟适应值重新指定:
比如指定第一层个体的虚拟适应值为1,第二层个体的虚拟适应值应该相应减少,可取为0.9,依此类推。这样,可使虚拟适应值规范化。保持优良个体适应度的优势,以获得更多的复制机会,同时也维持了种群的多样性。
NSGA采用的非支配分层方法,可以使好的个体有更大的机会遗传到下一代;适应度共享策略则使得准Pamto面上的个体均匀分布,保持了群体多样性,克服了超级个体的过度繁殖,防止了早熟收敛。算法流程如图所示:
非支配排序遗传算法(NSGA)在许多问题上得到了应用。但NSGA仍存在一些问题:
a) 计算复杂度较高,为(m为目标函数个数,N为种群大小),所以当种群较大时,计算相当耗时。
b) 没有精英策略;精英策略可以加速算法的执行速度,而且也能在一定程度上确保已经找到的满意解不被丢失。
c) 需要指定共享半径。
2000年,Deb又提出NSGA的改进算法一带精英策略的非支配排序遗传算法(NSGA-II),针对以上的缺陷通过以下三个方面进行了改进:
a) 提出了快速非支配排序法,降低了算法的计算复杂度。由原来的降到
,其中,m为目标函数个数,N为种群大小。
b) 提出了拥挤度和拥挤度比较算子,代替了需要指定共享半径的适应度共享策略,并在快速排序后的同级比较中作为胜出标准,使准Pareto域中的个体能扩展到整个Pareto域,并均匀分布,保持了种群的多样性。
c) 引入精英策略,扩大采样空间。将父代种群与其产生的子代种群组合,共同竞争产生下一代种群,有利于保持父代中的优良个体进入下一代,并通过对种群中所有个体的分层存放,使得最佳个体不会丢失,迅速提高种群水平。
NSGA-II对第一代算法中非支配排序方法进行了改进:对于每个个体 i 都设有以下两个参数 n(i) 和 S(i),
n(i) 为在种群中支配个体 i 的解个体的数量。(别的解支配个体 i 的数量)
S(i) 为被个体 i?所支配的解个体的集合。(个体 i 支配别的解的集合)
1) 首先,找到种群中所有 n(i)=0 的个体(种群中所有不被其他个体至配的个体 i),将它们存入当前集合F(1);(找到种群中所有未被其他解支配的个体)
2) 然后对于当前集合 F(1) 中的每个个体 j,考察它所支配的个体集 S(j),将集合 S(j) 中的每个个体 k 的 n(k) 减去1,即支配个体 k 的解个体数减1(因为支配个体 k 的个体 j 已经存入当前集 F(1) );(对其他解除去被第一层支配的数量,即减一)
3) 如 n(k)-1=0则将个体 k 存入另一个集H。最后,将 F(1) 作为第一级非支配个体集合,并赋予该集合内个体一个相同的非支配序 i(rank),然后继续对 H 作上述分级操作并赋予相应的非支配序,直到所有的个体都被分级。其计算复杂度为,m为目标函数个数,N为种群大小。(按照1)、2)的方法完成所有分级)
在原来的NSGA中,我们采用共享函数以确保种群的多样性,但这需要由决策者指定共享半径的值。为了解决这个问题,我们提出了拥挤度概念:在种群中的给定点的周围个体的密度,用 ?表示,它指出了在个体 i 周围包含个体 i 本身但不包含其他个体的长方形(以同一支配层的最近邻点作为顶点的长方形)
如图所示:
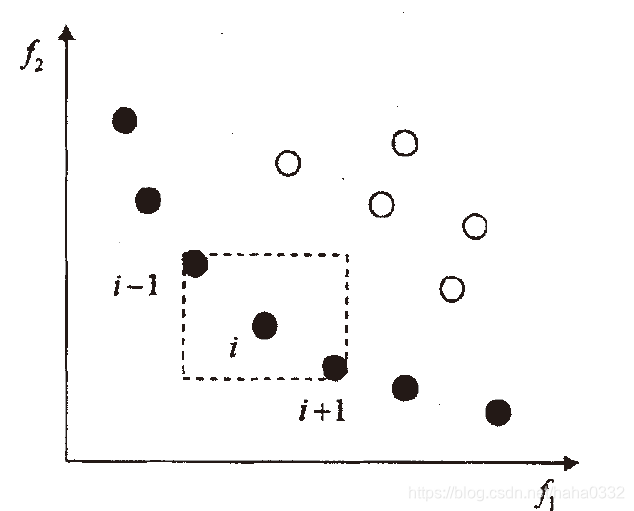
拥挤度比较算子:?
从图中我们可以看出??值较小时表示该个体周围比较拥挤。为了维持种群的多样性,我们需要一个比较拥挤度的算予以确保算法能够收敛到一个均匀分布的Pareto面上。
由于经过了排序和拥挤度的计算,群体中每个个体 i 都得到两个属性:非支配序 i(rank) 和拥挤度?,则定义偏序关系
:当满足条件 i(rank) <?
,或满足 i(rank) =?
?且
>?
。时,定义
,。也就是说:如果两个个体的非支配排序不同,取排序号较小的个体(分层排序时,先被分离出来的个体);如果两个个体在同一级,取周围较不拥挤的个体。
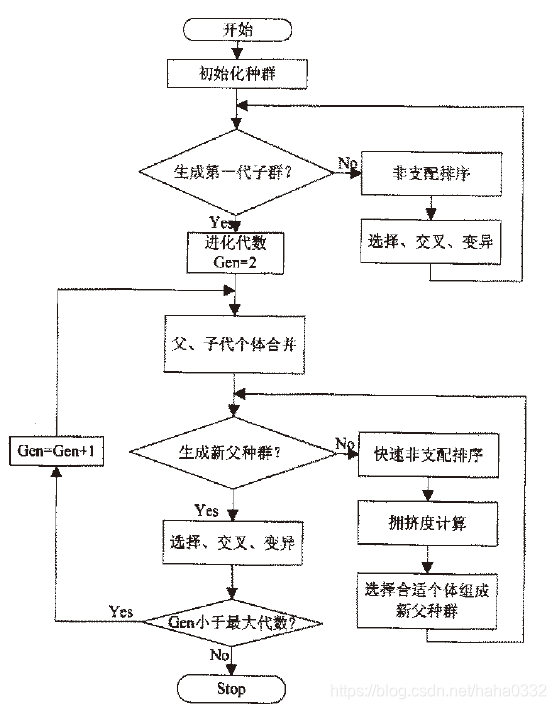
首先,随机初始化一个父代种群P(0),并将所有个体按非支配关系排序且指定一个适应度值,如:可以指定适应度值等于其非支配序 i(rank),则1是最佳适应度值。然后,采用选择、交叉、变异算子产生下一代种群Q(0),大小为N。
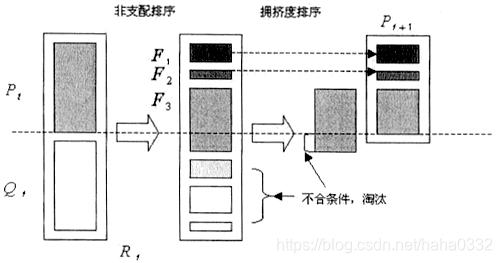
如图,首先将第 t 代产生的新种群Q(t)与父代P(t)合并组成R(t),种群大小为2N。然后R(t)。进行非支配排序,产生一系列非支配集 F(t) 并计算拥挤度。由于子代和父代个体都包含在 R(t) 中,则经过非支配排序以后的非支配集 F(1) 中包含的个体是 R(t) 中最好的,所以先将 F(1) 放入新的父代种群 P(t+1) 中。如果 F(1) 的大小小于N,则继续向 P(t+1) 中填充下一级非支配集 F(2),直到添加 F(3) 时,种群的大小超出N,对 F(3) 中的个体进行拥挤度排序(sort(F(3),)),取前
个个体,使 P(t+1) 个体数量达到N。然后通过遗传算子(选择、交叉、变异)产生新的子代种群 Q(t+1)。
算法的整体复杂性为,由算法的非支配排序部分决定。
通过介绍非支配排序遗传算法(NSGA)及其改进算法NSGA-II的基本原理和流程,我们了解到NSGA-II解决了NSGA中存在的3个问题:降低了计算复杂度;引入精英策略;采用拥挤度及其比较算子代替了共享半径。使得NSGA-Ⅱ在处理多目标优化问题上有更好的性能。
NSGA-Ⅱ的matlab程序下载:
1. 使用积分下载路径:Matlab编写多目标优化算法NSGA-Ⅱ的详解以及论文详解
2. 单次付费下载路径:Matlab编写NSGA-2多目标优化算法_非支配排序遗传算法-机器学习文档类资源-CSDN下载
(有读者反映,使用积分下载时,对于没有积分的童鞋一次性买积分费用过高,因此提供单次付费下载路径)
参考文献:










